Professional Summary
With over 4+ years of experience in Research and Development, 250+ google scholar citations, and a master’s degree in Machine Intelligence, I currently serve as a data scientist at Philips Innovation Strategy, where my work is driven by a commitment to enhancing patient outcomes. Collaborating closely with clinical scientists and data architects, I analyze complex numerical, textual, and image datasets to de- velop machine learning models that prioritize patient impact. Previously, I worked as a researcher at TCS Innovation Lab, focusing on developing NLP-based models for intent detection and discovery using large language models (LLMs). Additionally, I gained hands-on experience during my internship at IIT Gandhinagar, where I worked on the development of energy disaggregation algorithms, specifically utilizing the Non-Intrusive Load Monitoring Toolkit (NILMTK) for smart buildings.
- My Research interests include:
- Image processing ∩ MRI
- Deep learning ∩ Natural Language processing
- Application of Unsupervised and Semi-Supervised methods on real world problems
- Business Analytics ∩ Machine Learning
- My Skills include:
- Research and Development (R&D)
- Pytorch, Keras, LLM
- Natural Language Processing (NLP), Image Processing
- Deep Learning
- C, C++, SQL (Programming Language)
- Business Intelligence, Analytics
- Azure DevOps
- Microsoft Power BI, Qlik Sense
- AWS SageMaker
कर्मण्येवाधिकारस्ते मा फलेषु कदाचन।
मा कर्मफलहेतुर्भूर्मा ते सङ्गोऽस्त्वकर्मणि॥
Can’t put the phenomenal experience of holding a meaningful pathway ahead after being a sincere M. Tech student at Dhirubhai Ambani Institute of Information and Communication Technology in a few lines. I was supervised by Prof. Amit Mankodi and co-supervised by Dr. Amit Bhatt and Dr. Bhaskar Chaudhary.
<The DREAM that one sees should be BIG enough and WORK-OUT harder to achieve them. Further, I don't perceive a distinction between Time-Pass and Passing-The-Time. I believe learning new things is an immeasurable time pass. By the way, to let you know, Success is a Social-Construct.>
Interests
- Artificial Intelligence
- Natural Language Processing
- Data Science
- MRI Imaging
- Image Processing
- Innovation Planning
- Innovation Efficiency
- Business Analytics
Education
M. Tech in Machine Intelligence, 2020
DA-IICT, Gandhinagar, India
B. Tech in Computer Science, 2017
GKV, Haridwar, India
Skills
Python
90%
Statistics
80%
Tensorflow
90%
PyTorch
80%
C++
90%
AWS SageMaker
60%
Azure DevOps Board
70%
Power BI Tool
60%
Docker
60%
Kubernetes
60%
React-JS
60%
Qlik Sense
80%
Experience
Data Scientist II
Philips Innovation
Researcher
Tata Consultancy Services
- Worked in the NLP subgroup of the Deep Learning and AI group.
- Have published and patented my work on the Intent Detection and Discovery Problem, which was presented as a main track at the highly-regarded NAACL (A rated) Conference.
- Tools: Google-Colab, Python, Pytorch, Keras, Jupyter Notebook, GitHub, Docker
Summer Research Intern
IIT Gandhinagar
Teaching Assistant
Dhirubhai Ambani Institute of Information and Communication Technology
Summer Research Intern
Raman Classes
Accomplishments
Certificate of Excellence in Reviewing
See certificateACM Certificate of Participation
See certificateFlipkart Grid Challenge (Level 1)
See certificateSummer Research Internship
See certificateFundamentals of Deep Learning for Computer Vision
See certificateForum for Information Retrieval Evaluation
See certificateSEO Bootcamp
See certificateAll India Inter University Judo Tournament
Gold Medal for scoring 94.8%
See certificateLatest News
Recent Posts
Philips Research Interview Experience


Creating a Conda Installer for NILMTK during SRIP @ IIT- GN
Projects
M. Tech Project @ DA-IICT


Featured Publications
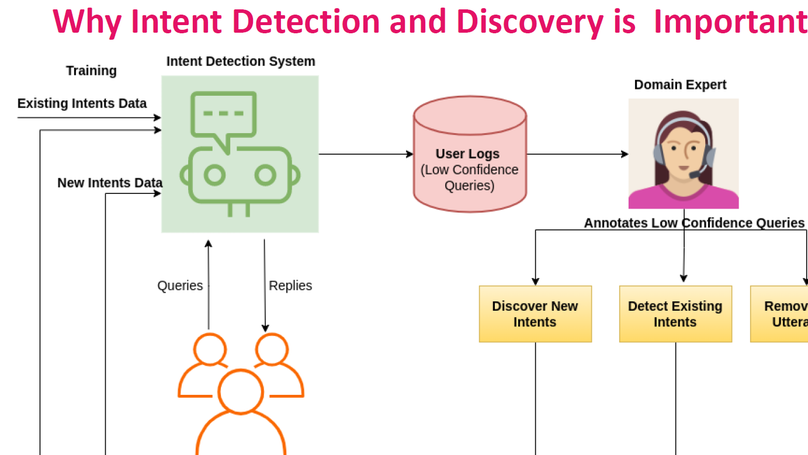
Intent Detection and Discovery from User Logs via Deep Semi-Supervised Contrastive Clustering
Intent Detection is a crucial component of Dialogue Systems wherein the objective is to classify a user utterance into one of multiple pre-defined intents. A pre-requisite for developing an effective intent identifier is a training dataset labeled with all possible user intents. However, even skilled domain experts are often unable to foresee all possible user intents at design time and for practical applications, novel intents may have to be inferred incrementally on-the-fly from user utterances. Therefore, for any real-world dialogue system, the number of intents increases over time and new intents have to be discovered by analyzing the utterances outside the existing set of intents. In this paper, our objective is to i) detect known intent utterances from a large number of unlabeled utterance samples given a few labeled samples and ii) discover new unknown intents from the remaining unlabeled samples. Existing SOTA approaches address this problem via alternate representation learning and clustering wherein pseudo labels are used for updating the representations and clustering is used for generating the pseudo labels. Unlike existing approaches that rely on epoch wise cluster alignment, we propose an end-to-end deep contrastive clustering algorithm that jointly updates model parameters and cluster centers via supervised and self-supervised learning and optimally utilizes both labeled and unlabeled data. Our proposed approach outperforms competitive baselines on five public datasets for both settings - (i) where the number of undiscovered intents are known in advance, and (ii) where the number of intents are estimated by an algorithm. We also propose a human-in-the-loop variant of our approach for practical deployment which does not require an estimate of new intents and outperforms the end-to-end approach.
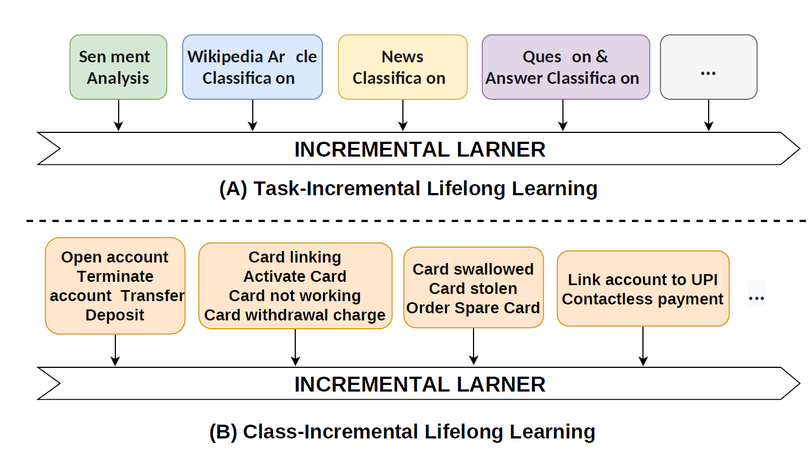
Prompt Augmented Generative Replay via Supervised Contrastive Learning for Lifelong Intent Detection
Identifying all possible user intents for a dialog system at design time is challenging even for skilled domain experts. For practical applications, novel intents may have to be inferred incrementally on the fly. This typically entails repeated retraining of the intent detector on both the existing and novel intents which can be expensive and would require storage of all past data corresponding to prior intents. In this paper, the objective is to continually train an intent detector on new intents while maintaining performance on prior intents without mandating access to prior intent data. Several data replay-based approaches have been introduced to avoid catastrophic forgetting during continual learning, including exemplar and generative replay. Current generative replay approaches struggle to generate representative samples because the generation is conditioned solely on the class/task label. Motivated by the recent work around prompt-based generation via pre-trained language models (PLMs), we employ generative replay using PLMs for incremental intent detection. Unlike exemplar replay, we only store the relevant contexts per intent in memory and use these stored contexts (with the class label) as prompts for generating intent-specific utterances. We use a common model for both generation and classification to promote optimal sharing of knowledge across both tasks. To further improve generation, we employ supervised contrastive fine-tuning of the PLM. Our proposed approach achieves state-of-the-art (SOTA) for lifelong intent detection on four public datasets and even outperforms exemplar replay-based approaches. The technique also achieves SOTA on a lifelong relation extraction task, suggesting that the approach is extendable to other continual learning tasks beyond intent detection.
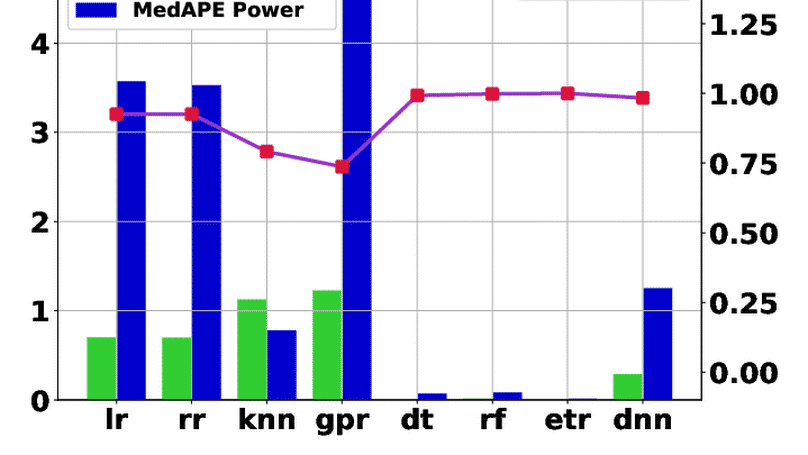
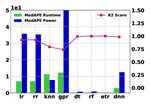
Modeling Performance and Power on Disparate Platforms using Transfer Learning with Machine Learning Models
Cross prediction is an active research area. Many research works have used cross prediction to predict the target system’s performance and power from the machine learning model trained on the source system. The source and target systems differ either in terms of instruction-set or hardware features. A widely used transfer learning technique utilizes the knowledge from a trained machine learning from one problem to predict targets in similar problems. In this work, we use transfer learning to achieve cross-system and cross-platform predictions. In cross-system prediction, we predict the physical system’s performance (runtime) and power from the simulation systems dataset while predicting performance and the power for target system from source system both having different instruction-set in cross-platform prediction. We achieve runtime prediction accuracy of 90% and 80% and power prediction accuracy of 75% and 80% in cross-system and cross-platform predictions, respectively, for the best performing deep neural network model. Furthermore , we have evaluated the accuracy of univariate and multivariate machine learning models, the accuracy of compute-intensive and data-intensive applications, and the accuracy of the simulation and physical systems.
Towards reproducible state-of-the-art energy disaggregation
In this paper, we have have described two key improvements to NILMTK; a rewritten model interface to simplify authoring of new disaggregation algorithms, and a new experiment API through which algorithmic comparisons can be specified with relatively little model knowledge. In addition, we have introduced NILMTKcontrib, a new repository containing 3 benchmarks and 9 modern disaggregation algorithms. In addition, such algorithms will be continuously evaluated in a range of pre-defined scenarios to produce an ongoing NILM competition
Recent Publications
Contact
- rajat.tech.002@gmail.com
- Reliance Circle, Gandhinagar, Gujarat
- Monday to Friday: 10:00 hrs to 17:00 hrs
- Book an appointment
- DM Me








